What is AWS S3?
AWS S3 or Simple Storage Service is an Object storage service that is built to store and retrieve any amount of data from anywhere. It is designed for 11 9's of durability. It is used for storing any kind of data in any format.
AWS S3 will be mostly used for the following uses:
- Store static web site contents like images, css etc
- Host entire static web site
- Store profile pictures
- Store images, documents, video or any other files uploaded by members
- Store files for ETL Processing
- Store logs
- Store backups
AWS S3 offers many features to secure stored data. As team developing AWS solutions and making use of S3 services, we have to understand and utilize the security controls offered by S3 to secure files related to product.
Which data should we secure in AWS S3?
- Rule of thumb should be to secure all data.
- Look for exceptions to the above rule and make it publicly accessible only for the exceptions, like
- Static web site contents - images and css
- Static web site hosting via S3
Securing Data at Rest.
- Disable public access to the S3 Bucket.
- Enable encryption on S3 Bucket using S3 Keys or AWS KMS (Key Management Service). This should be enabled in the beginning itself as it will not encrypt existing data.
- Enable versioning on S3 Bucket, this will help in compliance requirements and in recovering from accidental deletes and overwrites.
- Enable MFA on delete, this will also help in compliance requirements and add an extra measure of security on delete.
Securing Data in Transit:
Make sure all access to S3 data is secured using SSL/TLS inflight
Working on HIPAA Project consider following options for compliance:
- Restrict all delete
- Enable versioning
- Enable S3 access logs
- Setup custom trail in CloudTrail to track data events on S3
- Plan on storing CloudTrail logs in separate S3 bucket as they are maintained by CloudTrail for only 90 days.
Different Access Patterns for Reading from S3:
- Direct read from public S3 Bucket
- Read access to S3 Bucket via CloudFront
- Read access to S3 Object / File via S3 PreSignedUrl
- Read access to S3 Object / File via CloudFront PreSignedUrl
- Read access to S3 Files / Objects via API
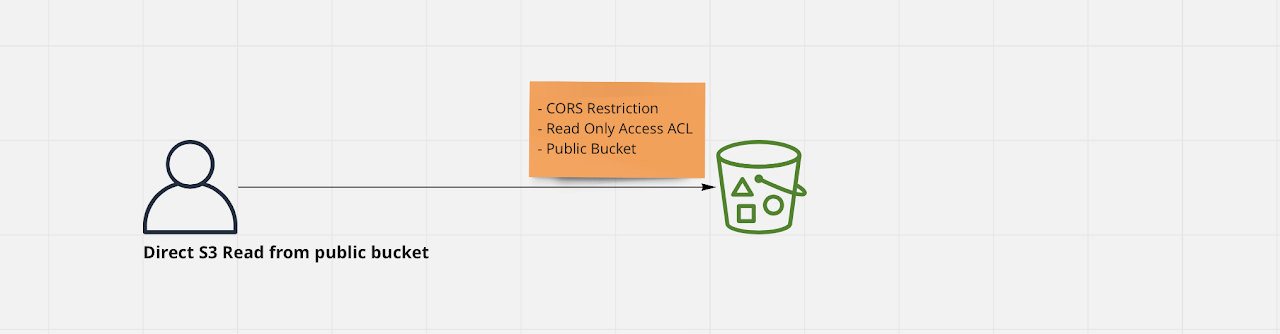
Direct read from public S3 Bucket
This pattern should only be applied if the content in the S3 does not need to be secure and can be made available publicly. Useful for content like static images and css files to be used on website. This pattern should not be used for file upload and the bucket should not have any public write access.
In this case Bucket is marked as publicly accessible, a CORS policy can be applied to restrict access from a particular website, and setup ACLs to ensure everyone has only Read permission.
Read access to S3 Bucket via CloudFront
This pattern should again only be applied if the content in the S3 does not need to be secure and can be made available publicly. Useful for content like static images and css files to be used on website and when you already have AWS CloudFront in place.
Using CloudFront you can restrict direct access to your S3 bucket and forces users to access only via CloudFront. Here S3 Bucket access is restricted via a CloudFront Origin Access Identity (OAI).

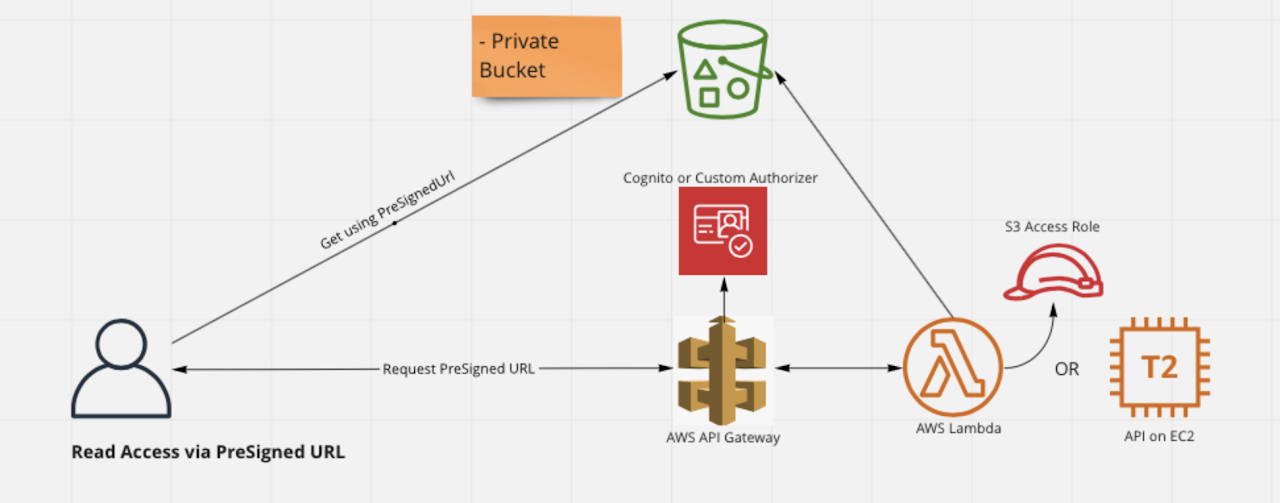
Read access to S3 Object / File via S3 PreSignedURL
This is a more secure pattern. Here, the Bucket data is not exposed to public. Any access to the Bucket data requires an API call which is responsible for providing a URL with a short expiry duration called PreSignedURL. Client can then make use of this PreSignedURL to get access to the specific Object in S3 Bucket for which this PreSigned URL was generated. You can implement this pattern with Lambda as API or with your Custom API hosted in EC2.
This also ensures that clients making call to API goes through Authorization check at AWS API Gateway. You can also do custom checks inside Lambda or in your API to ensure that user requesting access is indeed allowed to access this Object or file in S3.
This can be useful in scenarios like
- Users can only access their own document
- Parent can only access their own and their dependent's document
- Users can only access their departments documents to which they are associated
- Users can only access documents of the tenants that they belong to.
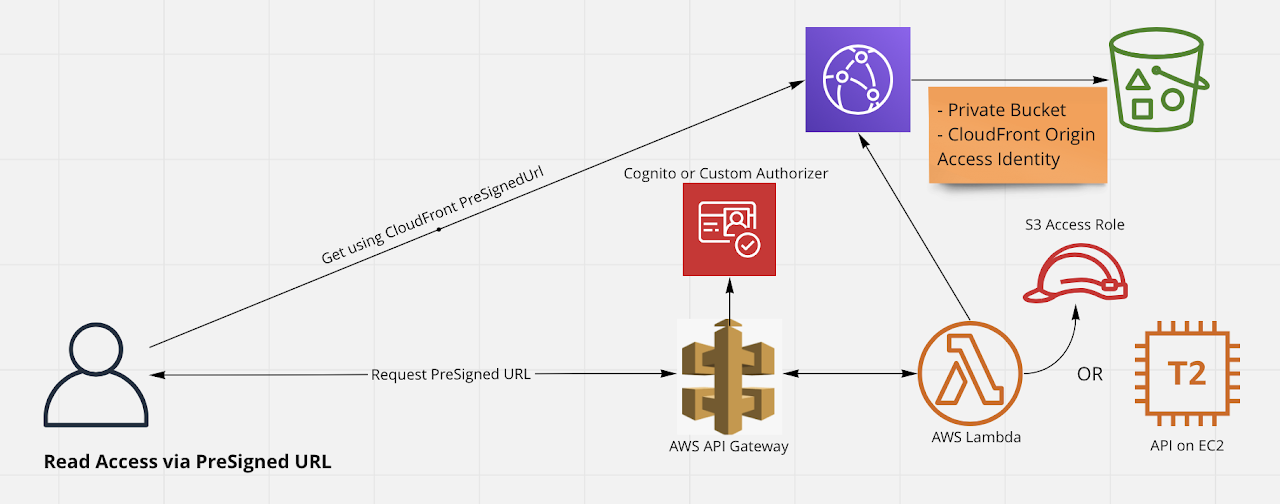
Read access to S3 Object / File via CloudFront PreSignedURL
This is also a secure read pattern and can be employed if you have a CloudFront Distribution setup. Here, the Bucket data is not exposed to public but only the CloudFront Distribution can access S3 Bucket, as S3 Bucket will be restricted via CloudFront Origin Access Identity. Further even the CloudFront files are protected from read access as it will expect a PreSigned URL for access. This is also implemented using Lambda as API or with your Custom API hosted in EC2.
This also ensures that clients making call to API goes through Authorization check at AWS API Gateway. You can also do custom checks inside Lambda or in your API to ensure that user requesting access is indeed allowed to access this Object or file in S3.
This can be useful in distribution of private media files.
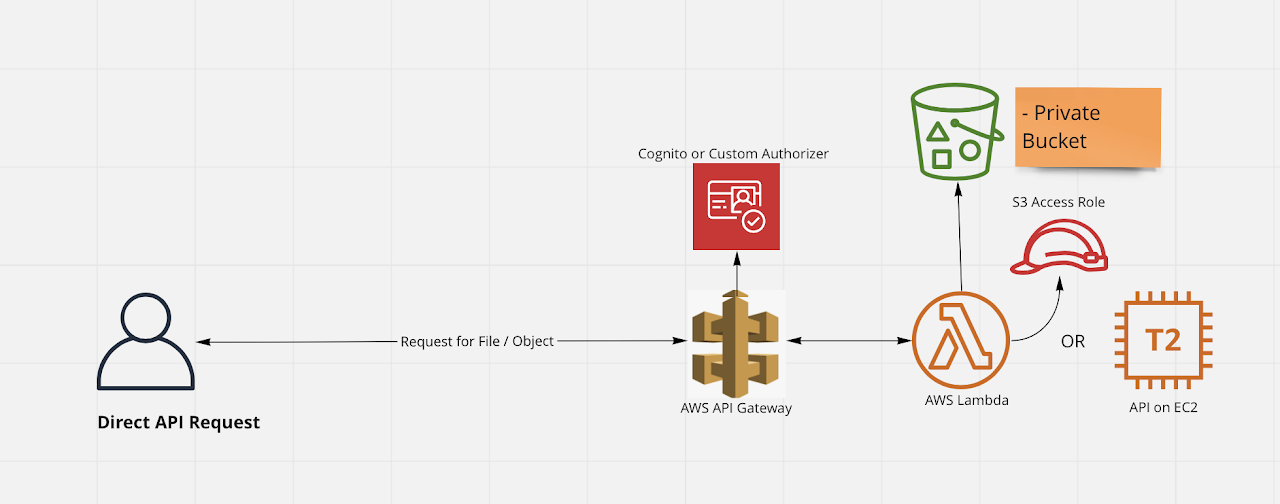
Read access to S3 Files / Objects via API
This is also a secure read pattern and can be employed if you can manage extra load on your API. This is because now your API is responsible for streaming file content to the requestor. Here S3 Bucket itself is not accessible directly.
This also ensures that clients making call to API goes through Authorization check at AWS API Gateway. You can also do custom checks inside Lambda or in your API to ensure that user requesting access is indeed allowed to access this Object or file in S3.
This can be useful in following cases
- When migrating existing APIs to cloud with minimal changes.
- When you have custom logic to validate if a file access is allowed at a given time by the user.
- When you have custom processing to be done before delivering the file from S3 and the logic already exists in your API
Different Write Patterns for Uploading to S3:
- Upload Files / Objects to S3 via S3 PreSignedUrl
- Upload Files / Objects to S3 via API
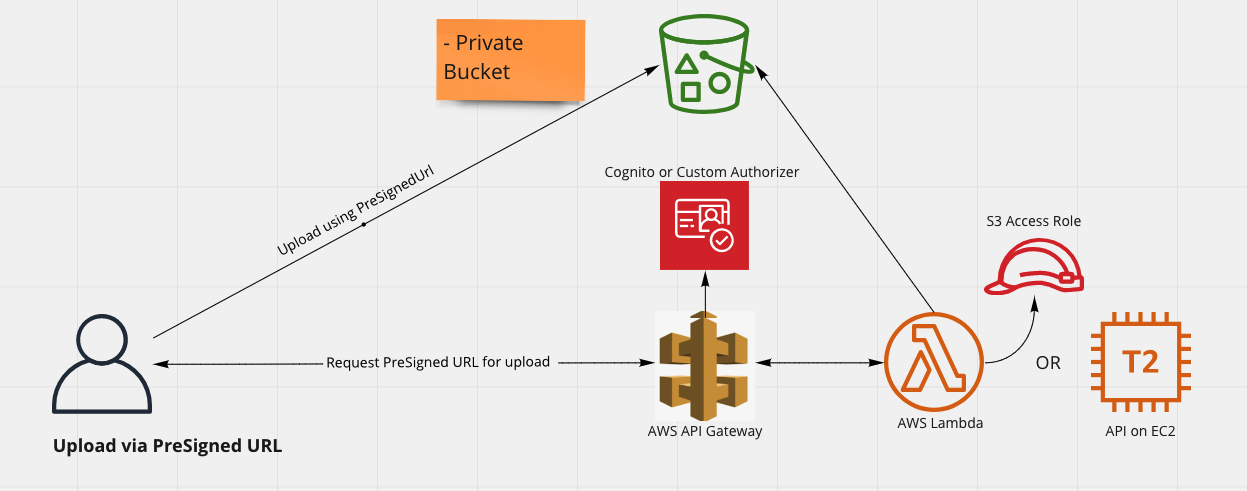
Upload Files / Objects to S3 via S3 PreSignedUrl
This is secure way to allow your users to upload files to S3. Here S3 Bucket itself is not accessible directly for uploading.
In this approach you setup a AWS Role that has write to upload files to your S3 bucket. You then associate this AWS Role to an EC2 machine or Lambda function so that it can generate PreSignedUrl for uploading purpose. Make sure that the validity time of this PreSignedUrl is not too long and not too short either.
This approach ensures that clients making call to API goes through Authentication and Authorization check at AWS API Gateway. You can also do custom checks inside Lambda or in your API to ensure that user requesting to upload is indeed allowed to upload an Object or file in S3.
This can be useful in following cases
- When you have custom logic to validate if a file upload is allowed at a given time by the user.
- When you have custom processing to be done before storing the file in S3 and the logic already exists in your API
Benefit of this approach is that your API does not get tied up with receiving file and uploading to S3, as they are being uploaded to S3 directly via PreSignedUrl
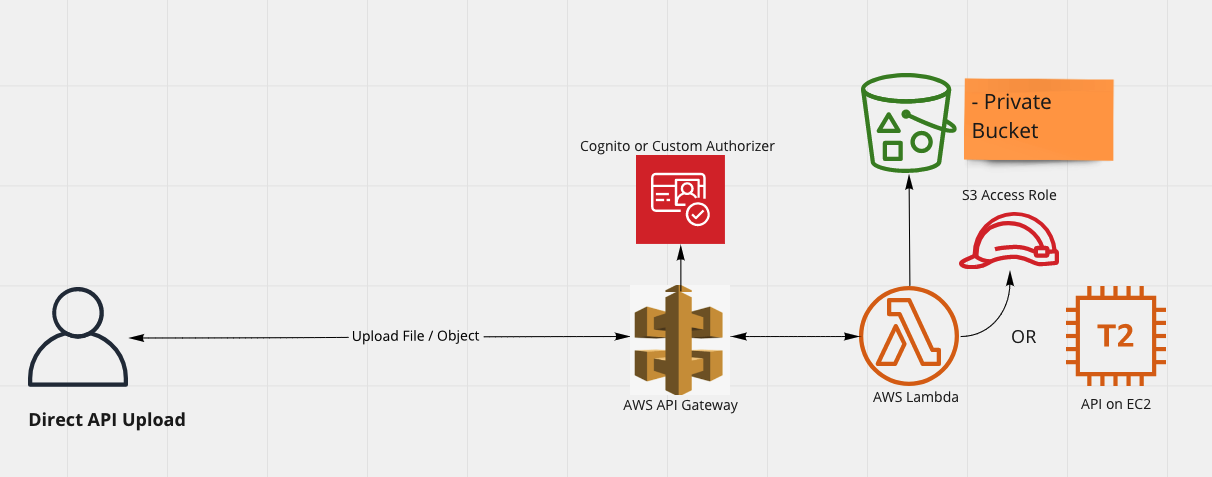
Upload Files / Objects to S3 via API
This is also a secure way to allow your users to upload files to S3. Here S3 Bucket itself is not accessible directly for uploading.
In this approach you setup an AWS Role that has write to upload files to your S3 bucket. You then associate this AWS Role to an EC2 machine or Lambda function so that it can upload files to S3 using S3 SDK.
This approach ensures that clients making call to API goes through Authentication and Authorization check at AWS API Gateway. You can also do custom checks inside Lambda or in your API to ensure that user requesting to upload is indeed allowed to upload an Object or file in S3.
This can be useful in following cases
- When migrating existing API with minimum changes
- When you have custom logic to validate if a file upload is allowed at a given time by the user.
- When you have custom processing to be done before storing the file in S3 and the logic already exists in your API
Only drawback with this approach is that it ties up your API to the upload process as it has to receive the file and then upload to S3.
Other access patterns:
- Using Cognito User pools and Identify pool to access and upload files from/to S3
- Using Cognito User pools and STS to get temporary access token to access S3
- Using STS to access S3 Across Account
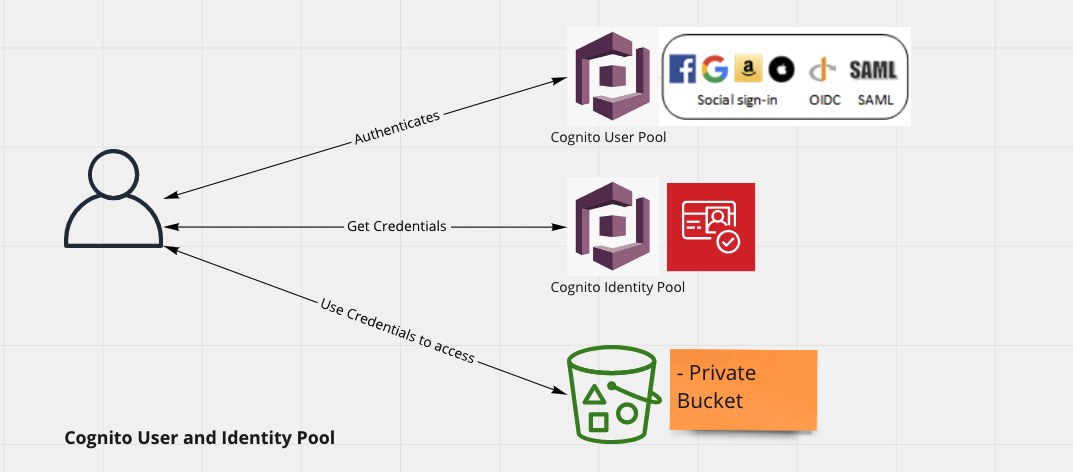
Using Cognito User Pools and Identity pooI to access and upload files from / to S3
This is also a secure way to allow your users to access / upload files from / to S3. Here S3 Bucket itself is not accessible directly.
In this approach you setup an AWS Cognito User pool which is responsible for authenticating users, an authenticated user then gets relevant credentials from AWS Cognito Identity pool which grants them access to S3 Bucket.
This approach ensures that clients making call to API goes through Authentication and Authorization AWS Cognito.
This can be useful in following cases
- When you are already using AWS Cognito User Pools
- When you are using ADFS
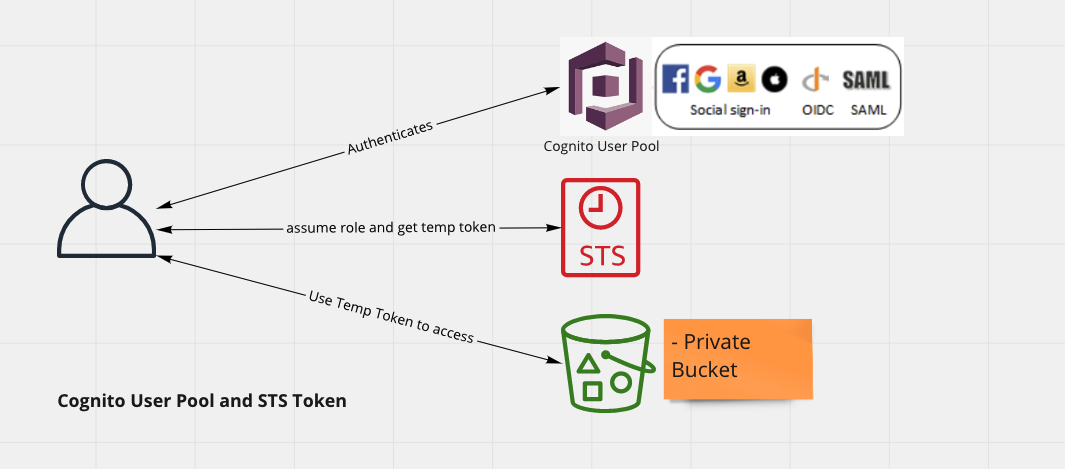
Using Cognito User Pools and STS to get temporary token to access S3
This is also a secure way to allow your users to access / upload files from / to S3. Here also S3 Bucket itself is not accessible directly.
In this approach you setup an AWS Cognito User pool which is responsible for authenticating users, you then make use of AWS STS services to request for a Temporary Token. This token is then used to access S3.
This approach ensures that clients making call to API goes through Authentication and are authorized for access via Temporary STS Tokens.
This can be useful in following cases
- When you are already using AWS Cognito User Pools and do not want to set them up as IAM Users
- When you do not want to use Federated Identity and instead rely on STS
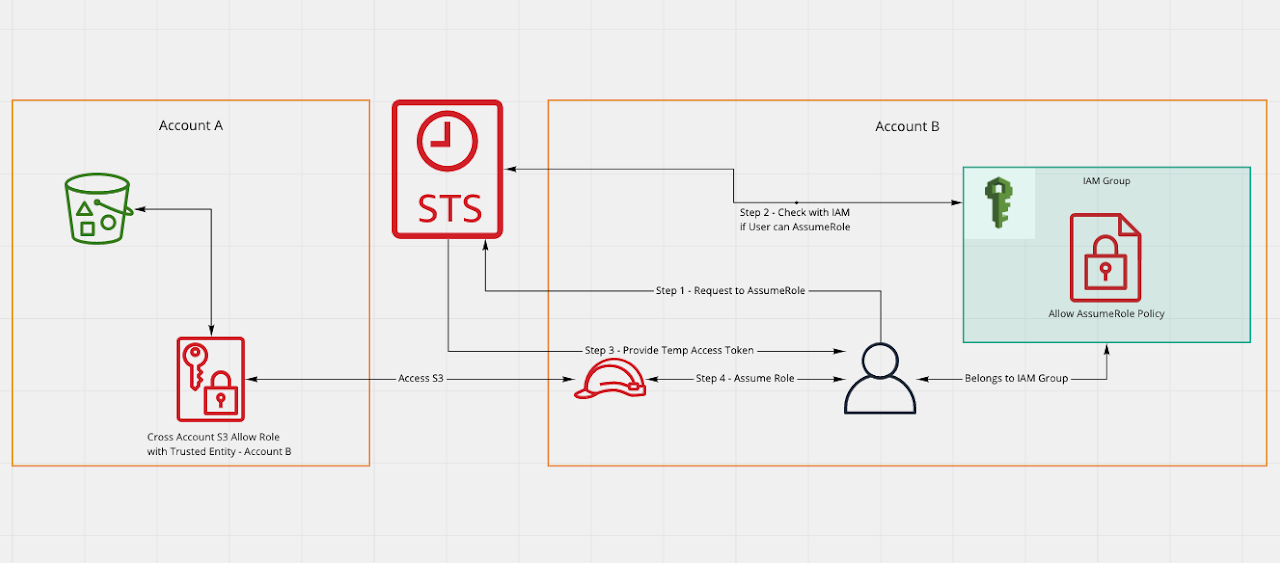
Using STS to access S3 across accounts
This is another unique scenario where you want users of another AWS account to access your account's S3 Bucket. In such a scenario we should not share credentials or create a IAM user into our account for other party. In such a case we setup something called as Cross Account Access Role.
Setting this up involves multiple steps:
- In Account A
- Create an IAM Role (say CrossAccountS3Access) with permission to access S3 bucket and provide Account B as the Trusted Entity.
- Share the ARN of this Role (say - 'arn:aws:iam::AccountAID:role/CrossAccountS3Access').
- In Account B
- Now Account B's owner should setup an IAM Group say CrossAccountS3Access
- Attach a policy that will allow IAM user's of this Group to issue sts:AssumeRole request to STS for Resource - 'arn:aws:iam::AccountAID:role/CrossAccountS3Access'
- Add Users who want to access Account A's S3 bucket to this IAM Group - CrossAccountS3Access
- Now Users can make request to STS to AssumeRole - CrossAccountS3Access from Account A and then be able to access S3 in Account A.
Accessing S3 from within AWS resources say EC2
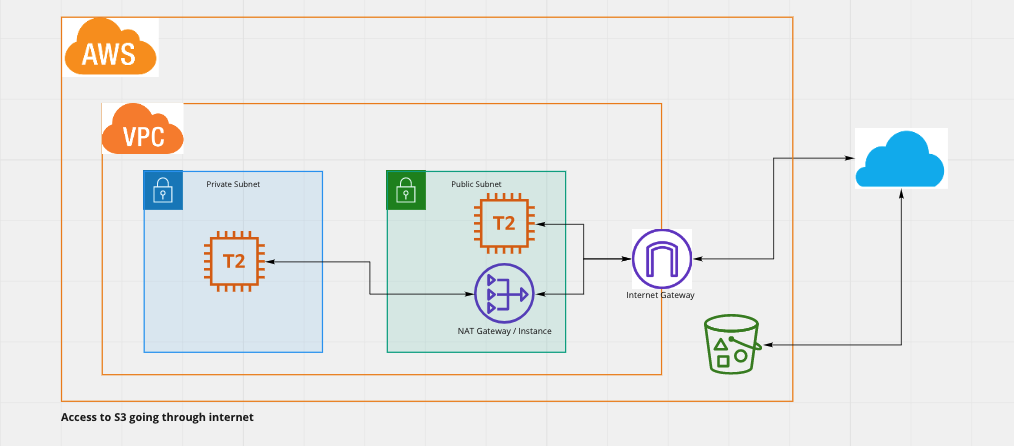
One last thing to think about is how to access S3 from within your AWS resources like say EC2. We have to understand this access pattern as if we are not careful then we end up with traffic to access S3 going through internet instead of keeping it inside the AWS. This also has cost implications. So lets take a look at this case.
By default when you try to access S3 from EC2 the request will be going out to internet then re-enter AWS to access S3 and then the response too will travel out to internet from S3 and then re-enter AWS and into your VPC and EC2 instance. This causes the object to travel via internet as part of the response and also you incur extra cost since AWS charges for all data leaving AWS to internet.
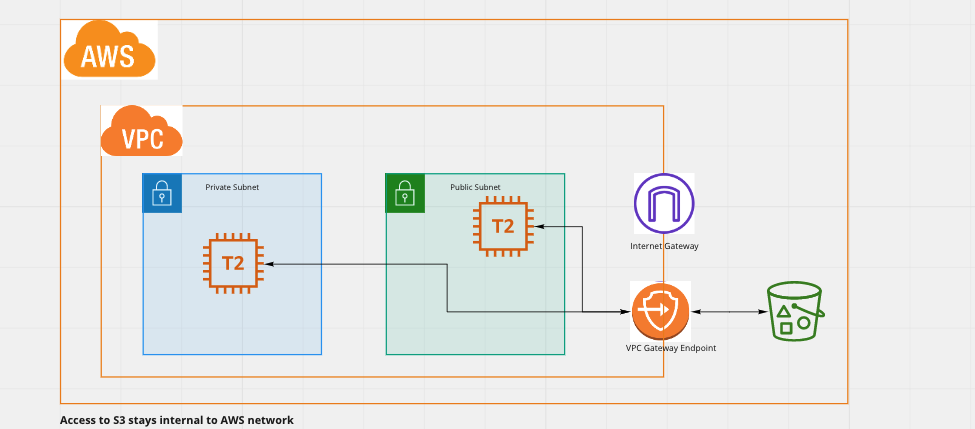
A better solution in this case would be to make use of VPC Endpoint Gateway for S3, since in this case the traffic does not leave AWS and makes use of private link to S3 from your VPC making it more secure.
Finally we would recommend that you fully secure your S3 from accidental deletion, overwrite, and leaks and also ensure that you are well covered from compliance and audit perspective.